(범주형 변수)
1. 명목형(Nominal)
: 서로 비교 가능한 등급이나 순서, 크기가 의미 없는 “독립적인“ 범주들로 구성
2. 순서형(Ordinal)
: 범주 사이에 명확한 순서가 존재하여 등급으로 나눌 수 있음
”범주형 변수를 왜 인코딩해야할까?“
: 머신러닝 모델들은 주로 수치형 데이터를 필요로 한다. 때문에 범주형 변수들을 모델들이 이해할 수 있는 형태로 변환(인코딩)해야함.
[인코딩 종류]
{sklearn의 Lable Encoding_ 레이블 인코딩}
: 범주형 변수의 각 카테고리에 고유한 정수를 할당하여 모델이 이해할 수 있는 형태로 데이터를 변환한다.
: 각 고유한 값에 대해서 사전식 순서에 따라 정렬한 후, 각 고유한 값에 대해 순차적인 정수 값을 할당한다.
(문제점)
: 등급 또는 순서로서의 의미를 학습과정에 담을 수 없음.
{Direct Mapping_직접 매핑하기}
: 순서형 범주형 변수의 경우, 범주의 순서를 고려하여 직접 매핑하는 것이 더 적합.
: ‘.dtype’을 통해 데이터 타입 확인
: ‘.unique()’을 통해 모든 고유 값을 확인함으로써 매핑이 올바르게 되었는지 검증.
{scikitr-learn의 Ordinary Encoder}
: 순서가 있는 범주형 데이터를 숫자로 매핑할 때 사용
: 이 클래스는 각 범주의 순서를 지정할 수 있음
*순서형 범주형 변수를 다룰 때 고려할 것*
(1) 고유 범주 수 축소
: 가능하다면 범주의 수 줄이기
: ex) 빈도수가 낮은 범주들을 더 큰 범주에 포함시키기 / 의미적으로 유사한 범주 합치기
==> 이렇게 하면 모델이 데이터를 더 잘 이해한다고 함. 복잡도를 감소시키는 것에서 실질적이고 효율적인 영향이 있다고 함.
(2) 직접 매핑 인코딩
: 순서형 범주형 변수 = Direct Mapping, Ordinary Encoder 사용하기
: 특히 Linear Regression, Ridge, Lasso
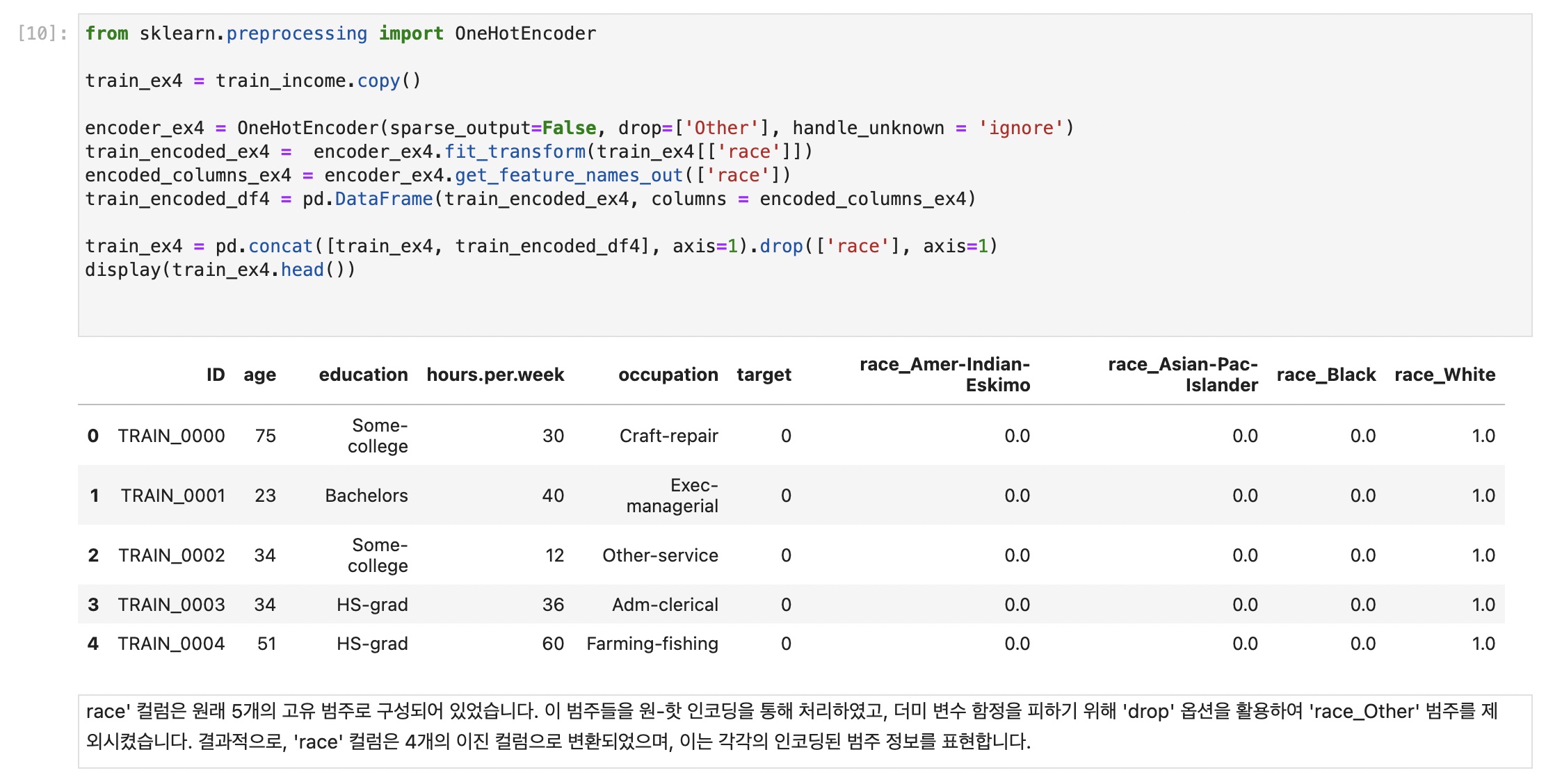
{One-Hot-Encoding_원 핫 인코딩}
: ‘범주형 데이터 -> 수치형 데이터’ 변환하는 기법
: 각 범주를 독립적인 이진 특성으로 변환함 (-> 이는 레이블 인코딩의 문제를 해결)

<Error!>
"Error : Found unknown categories ['Chevrolet'] in column 0 during transform"
해결법 : One Hot Encoder의 ‘handle_unknown=‘ignore’’매개변수 이용
“dummy(더미) 변수의 함정”
: 컬럼 간에 상호 의존적인 관계가 형성 되어 모델의 예측력을 저하시키고 해석을 어렵게 만든다
(해결법)
: One Hot Encoder의 drop 옵션‘
: drop = first -> 각 범주형 변수에서 첫 번쨰 범주를 제거하여 더미 변수의 함정을 방지한다.
{Binary Encoding_바이너리 인코딩}
: 데이터의 차원을 줄이면서 각 범주를 명확하게 표현 가능
'📙 Fundamentals > ML&DL' 카테고리의 다른 글
| 🏨 호텔 예약 정보 데이터셋 분석 | 2️⃣ 상관관계 분석 (0) | 2025.03.24 |
|---|---|
| 🏨 호텔 예약 정보 데이터셋 분석 | 1️⃣ 데이터 전처리 (0) | 2025.03.21 |
| 선형대수학이란 무엇이며, 왜 머신러닝/딥러닝에 필요한가? (0) | 2025.03.18 |
| 모델 경량화 | inceptionNet 정리 (0) | 2024.11.14 |
| 매니폴드 가설_Manifold hypothesis (0) | 2024.11.12 |