
GAN
: 두 개의 신경망 '생성자(Generator)'와 '판별자(Discriminator)'가 서로 경쟁하며 학습하는 비지도 학습(Unsupervised Learning) 방법
핵심 아이디어
: 생성자는 판별자를 속이기 위해 노력하고, 판별자는 생성자가 만든 가짜 이미지를 식별하기 위해 노력한다. 이러한 적대적인 관계는 두 모델이 도시에 발전하도록 자극하며, 결과적으로는 더 정교하고 현실적인 데이터를 생성할 수 있게 만든다.
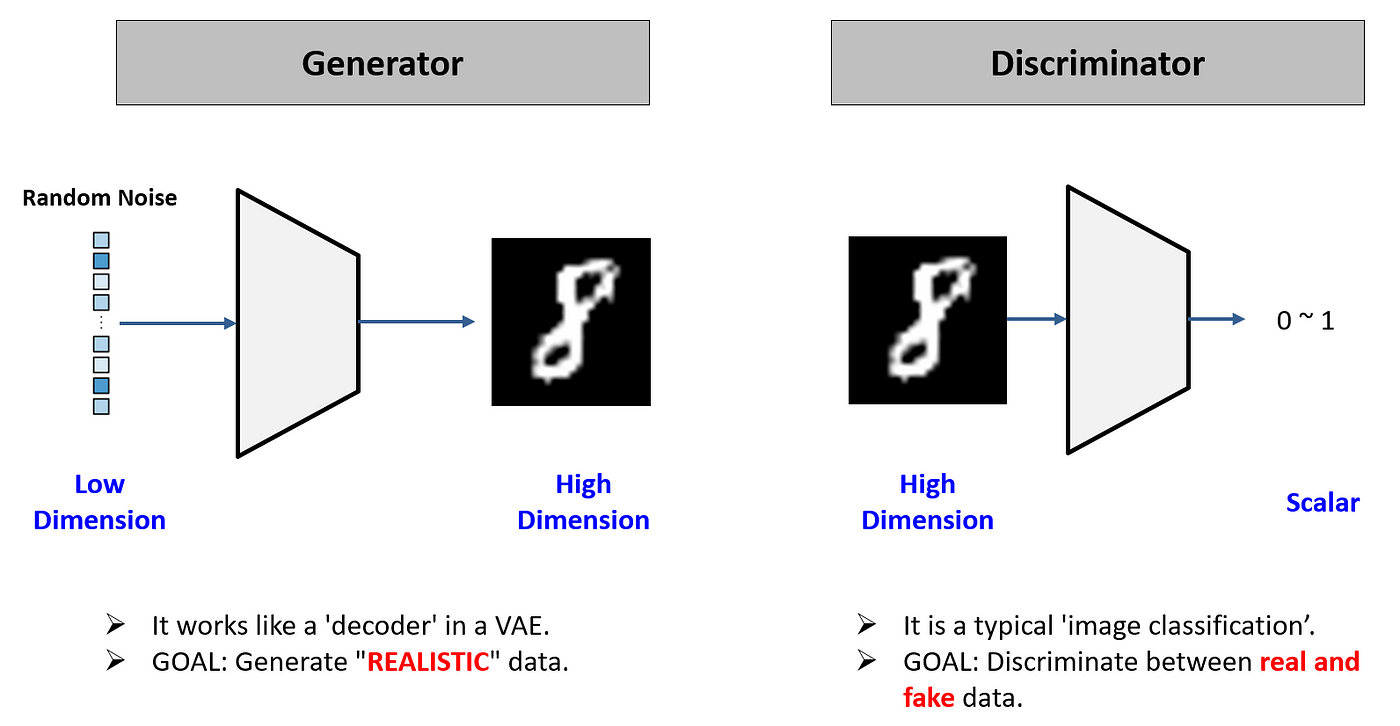
(구성 요소)
- 생성자(Generator) : 무작위 노이즈로부터 현실적인 데이터를 생성하려고 시도한다.
- 판별자(Discriminator) : 입력된 데이터가 실제 데이터인지 생성된 데이터인지를 구분하려고 한다.
손실함수

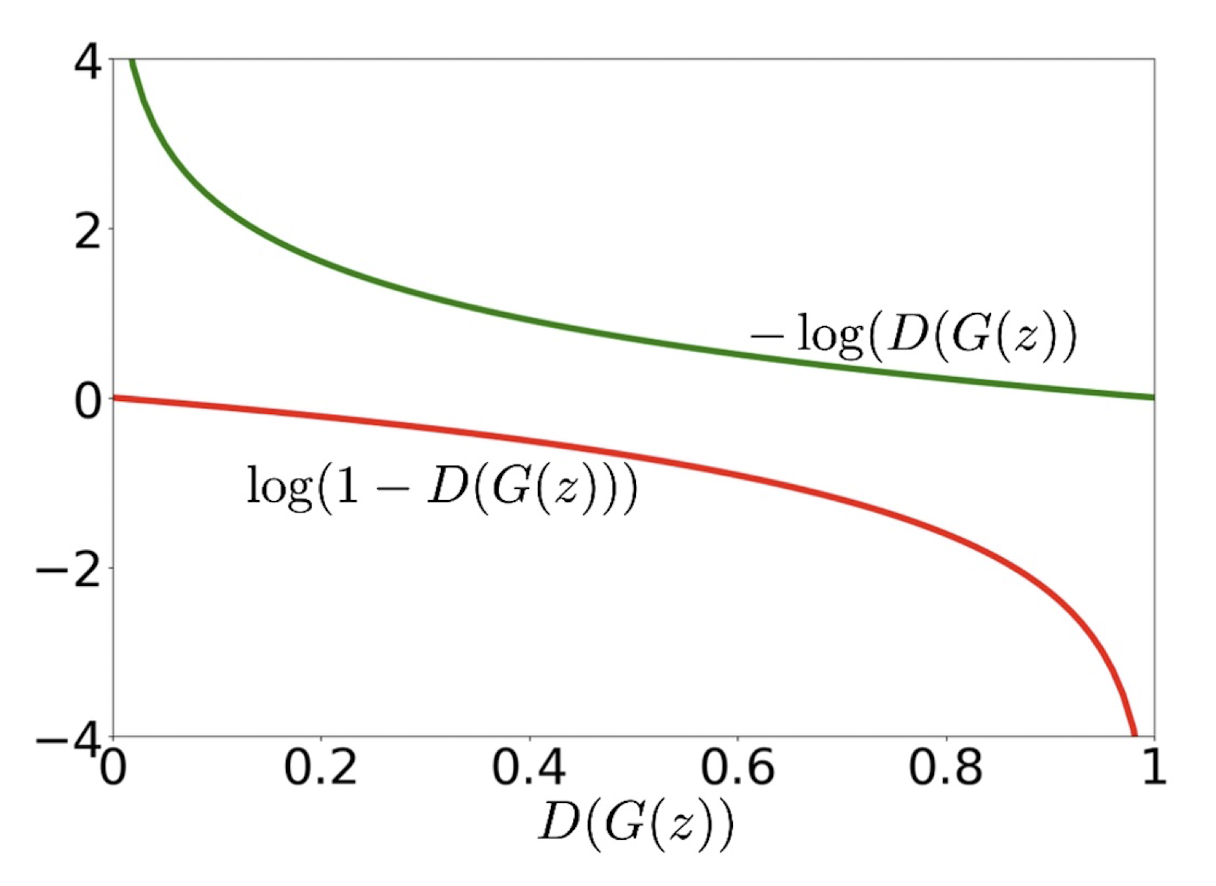
GAN에서 자주 발생하는 이슈
[학습 불안정성]
: 두 네트워크가 서로 다른 속도로 학습하거나, 한 쪽이 압도적으로 강해지면 학습이 망가질 수 있다.
: 적절한 초기화, Batch Normalization, Learning Rate 스케줄링, Gradient Penalty(WGAN-GP) 등
[모드 붕괴 (Mode Collapse)]
: 생성자가 특정 패턴의 가짜만 만들어서 판별자를 속이는 경우에 발생한다.
: 다양한 Noise Input 사용, Unrolled GAN, Mini-batch Discrimination 등
[손실값 모니터링의 어려움]
: GAN의 손실함수를 모니터링하기 어려워 학습 과정을 추적하는데 어려움이 있다. → 주관적 평가로 확인하고 판단해야 한다.
: 완벽한 지표는 아니며, 특정 상황에서 왜곡이 있을 수 있다.
출처
https://medium.com/@hugmanskj/gan%EC%97%90-%EB%8C%80%ED%95%9C-%EC%9D%B4%ED%95%B4-a073a5425ef2
'📙 Fundamentals > ML&DL' 카테고리의 다른 글
| [모델 최적화] 주요 기법 (0) | 2025.08.18 |
|---|---|
| [NLP] 텍스트 데이터 전처리 (Text Preprocessing) (0) | 2025.06.18 |
| 데이터 증강 (Data Augmentation) (0) | 2025.05.07 |
| 이미지 전처리 | 정규화 (Normalization) (0) | 2025.05.04 |
| 이미지 전처리 | 리사이징 (Resizing) (0) | 2025.05.04 |