
☑️ 데이터 분리
: 모델 학습에 사용할 컬럼 선택 / 입력 변수, 출력 변수 분리 / Train, Test 데이터 분할
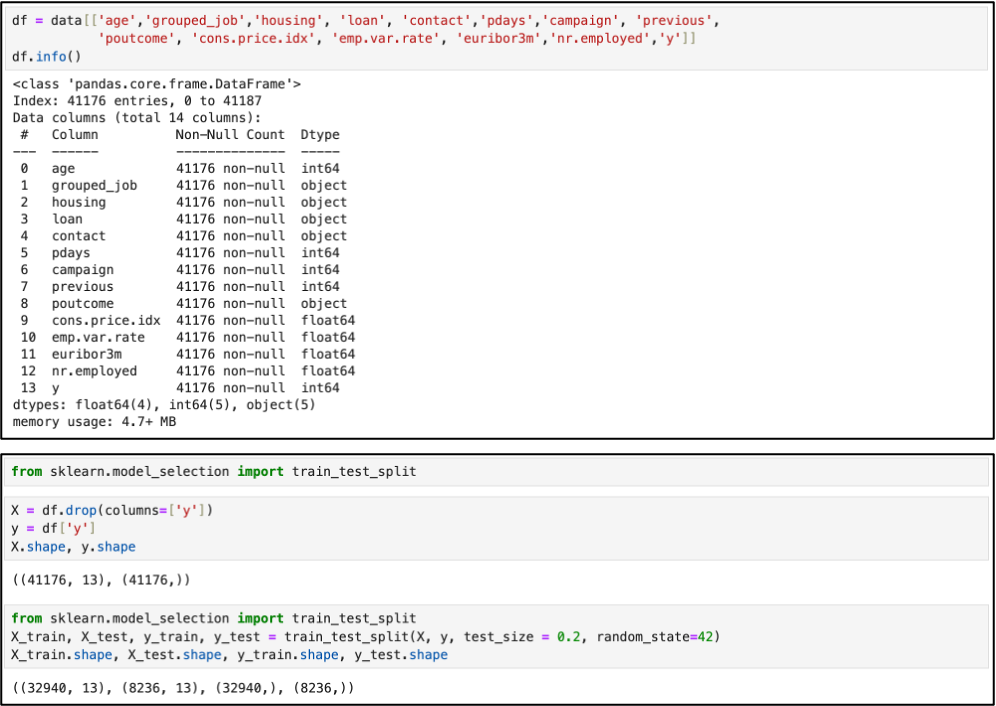
☑️ 라벨 인코딩
: 범주형 데이터 라벨 인코딩하기 (범주형 → 수치형)
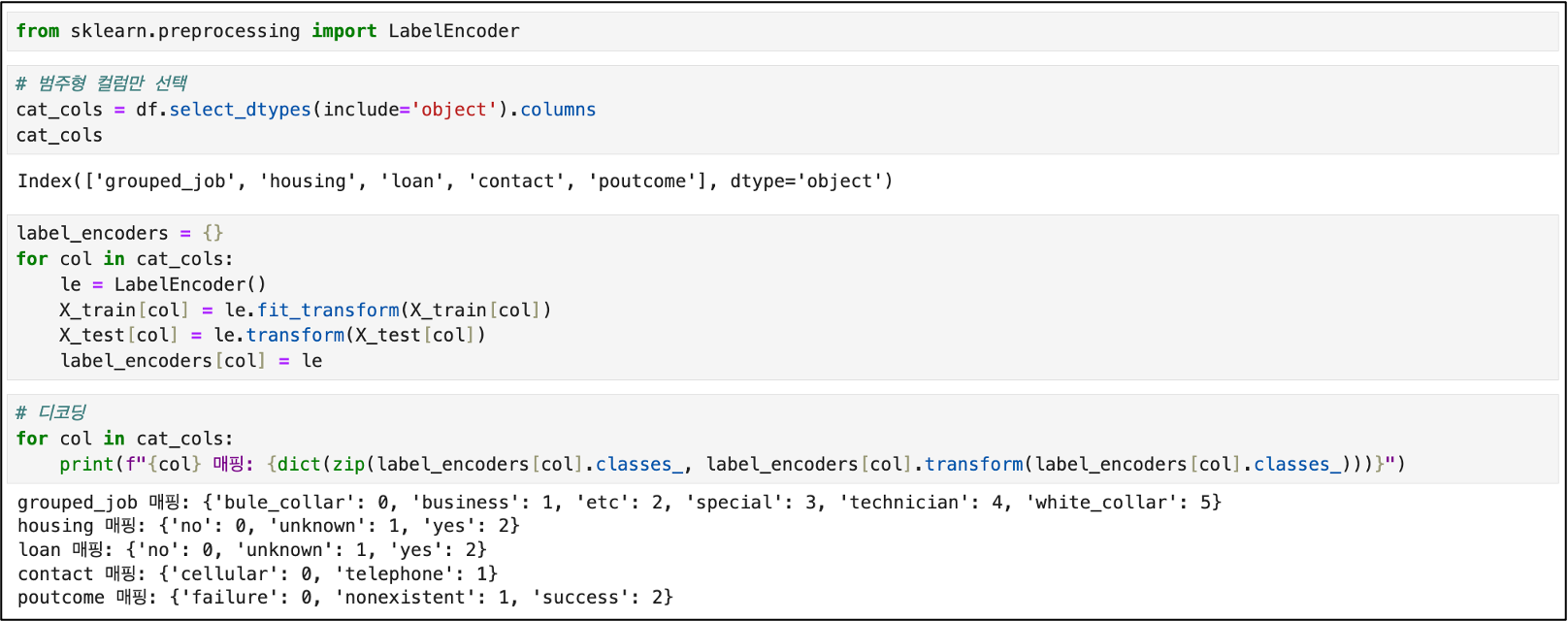
☑️ 트리 모델
(Decision Tree_결정트리 모델)

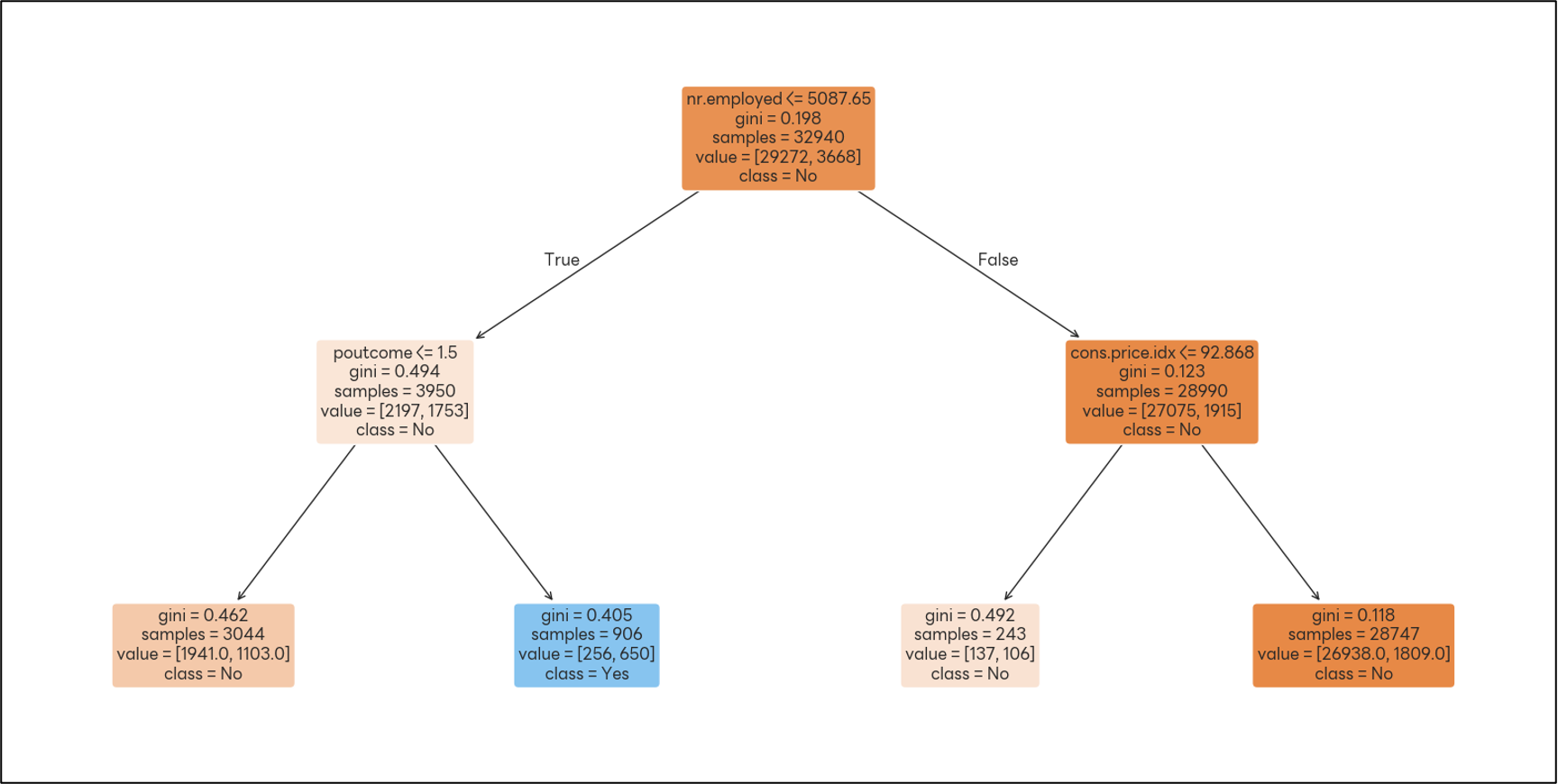
- 모델이 하나의 변수(nr.employed)에 과도하게 의존한다.
- 'euribor3m', 'emp.var.rate', 'previous', 'campaign' 등은 거의 쓰이지 않았고, 이들을 제거해도 성능 변화가 없을 수 있다.
- 의사결정 트리의 단점이 드러남. → 하나의 피처에 지나치게 의존해 분기가 단순해졌다.
- 가장 중요한 feature = nr.employed(고용된 사람 수) → (0.8) : 모델이 대부분 이 변수 하나만으로 예측 가능하다.
- 그다음으로 중요한 변수는 poutcome (과거 캠페인 결과), cons.price.idx(소비자 물가 지수)이고, 비중이 0.1 이하로 작다.
- 나머지 변수들은 0에 가깝고, 거의 의사 결정 트리에서 사용 안 한다.
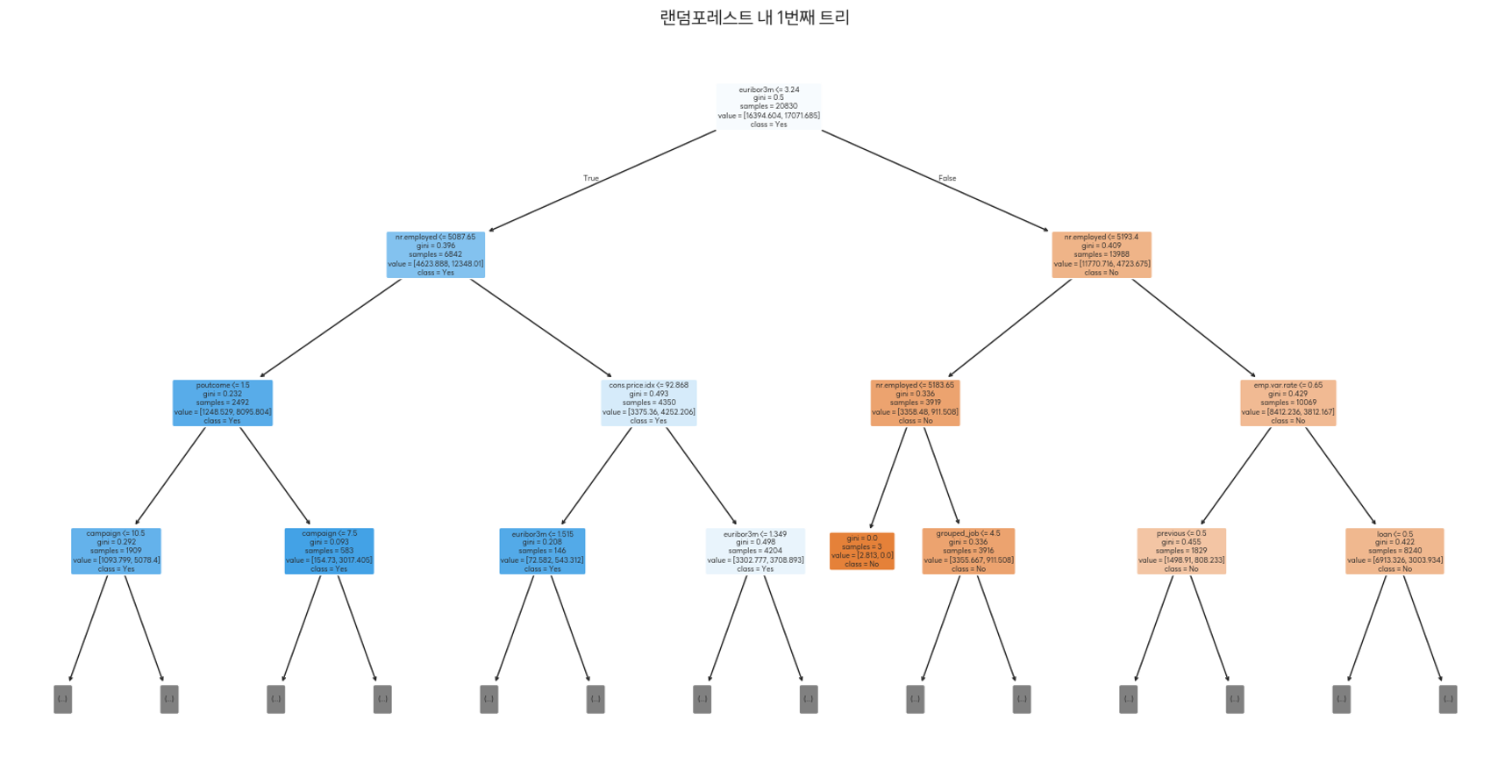
(결정 트리 시각화)
(Random Forest_랜덤 포레스트)
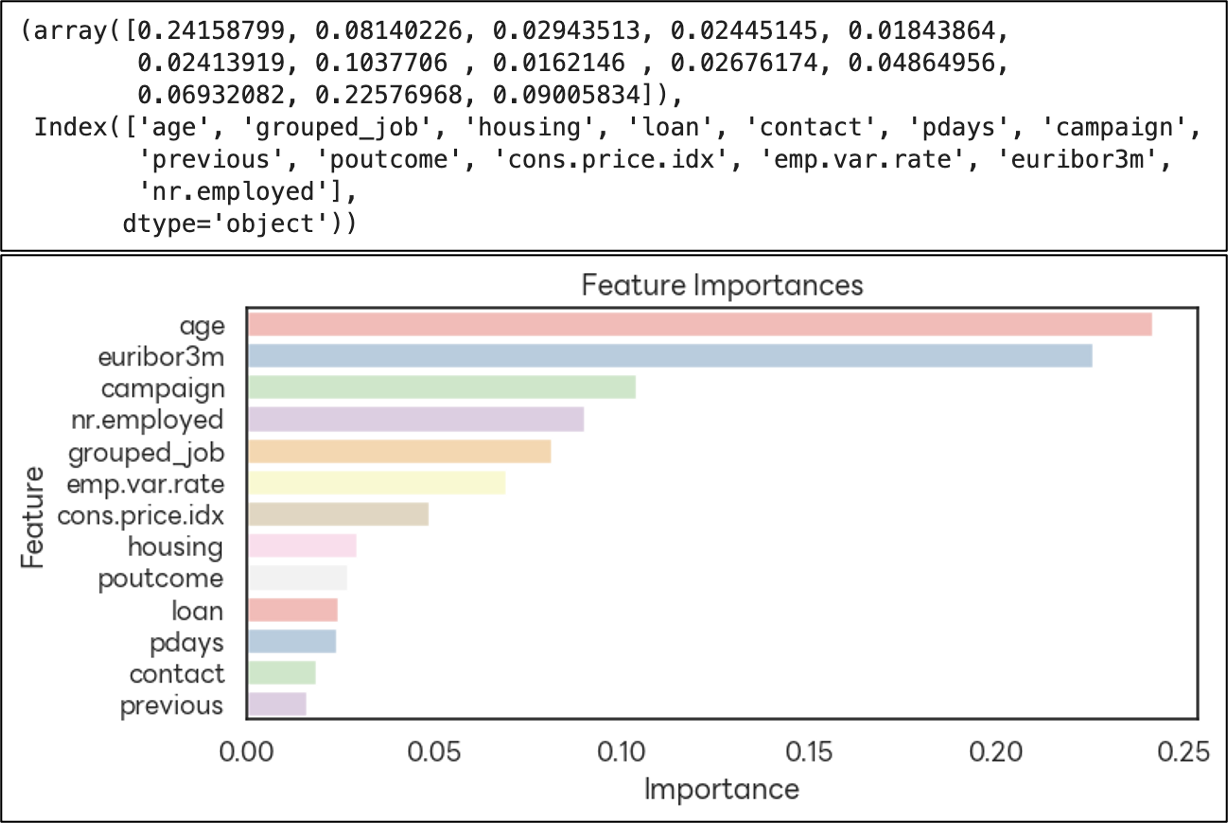
- (‘age’) : 나이가 많고 적음이 예금 가입 여부에 가장 큰 영향을 주는 것으로 보인다.
- (‘euribor3m’) : 유럽 기준금리로 경제적 요인이 큰 영향을 끼치는 것으로 보인다..
- (‘campaign’) : 마케팅 접촉 횟수가 중요 요인인 것 같다.
- (‘grouped_job’) : 직업군에 따른 행동 패턴 차이가 있을 수 있다.
- 개인 특성(age, job)과 경제적 지표(euribor3m, nr.employed, emp.var.rate) 그리고 마케팅 전략(campaign)에 민감하게 반응한다.
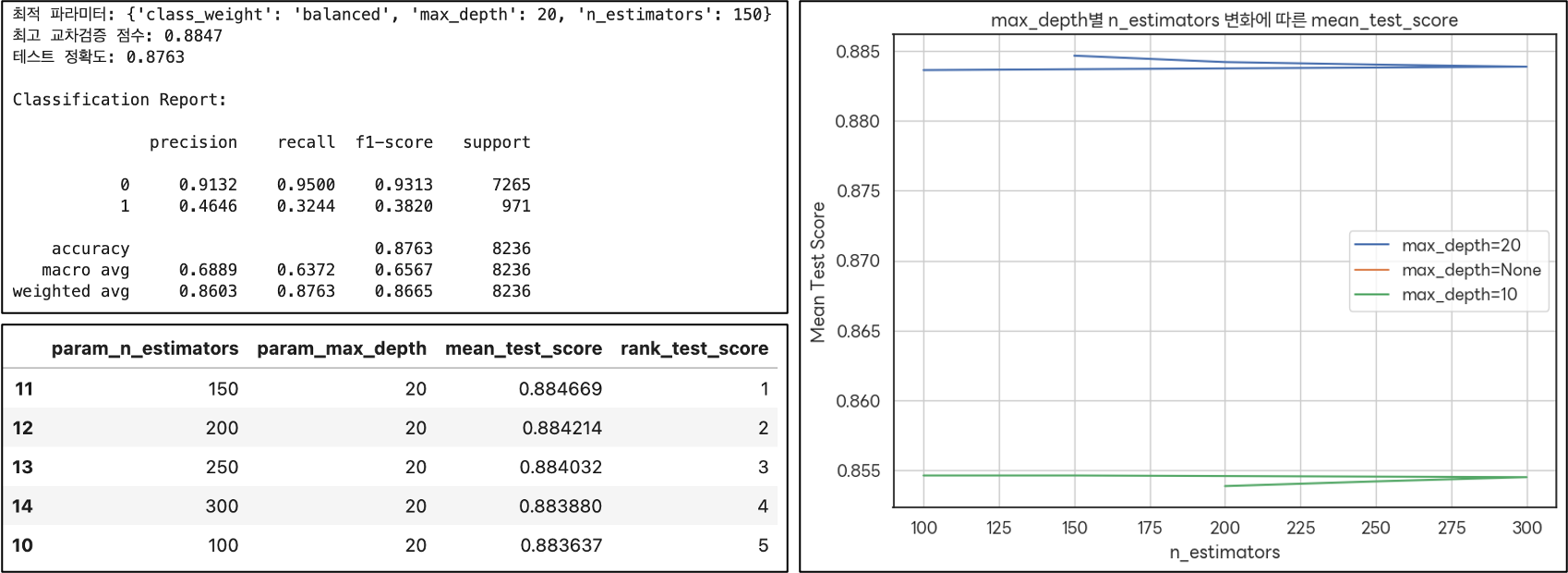
(XGBoost)
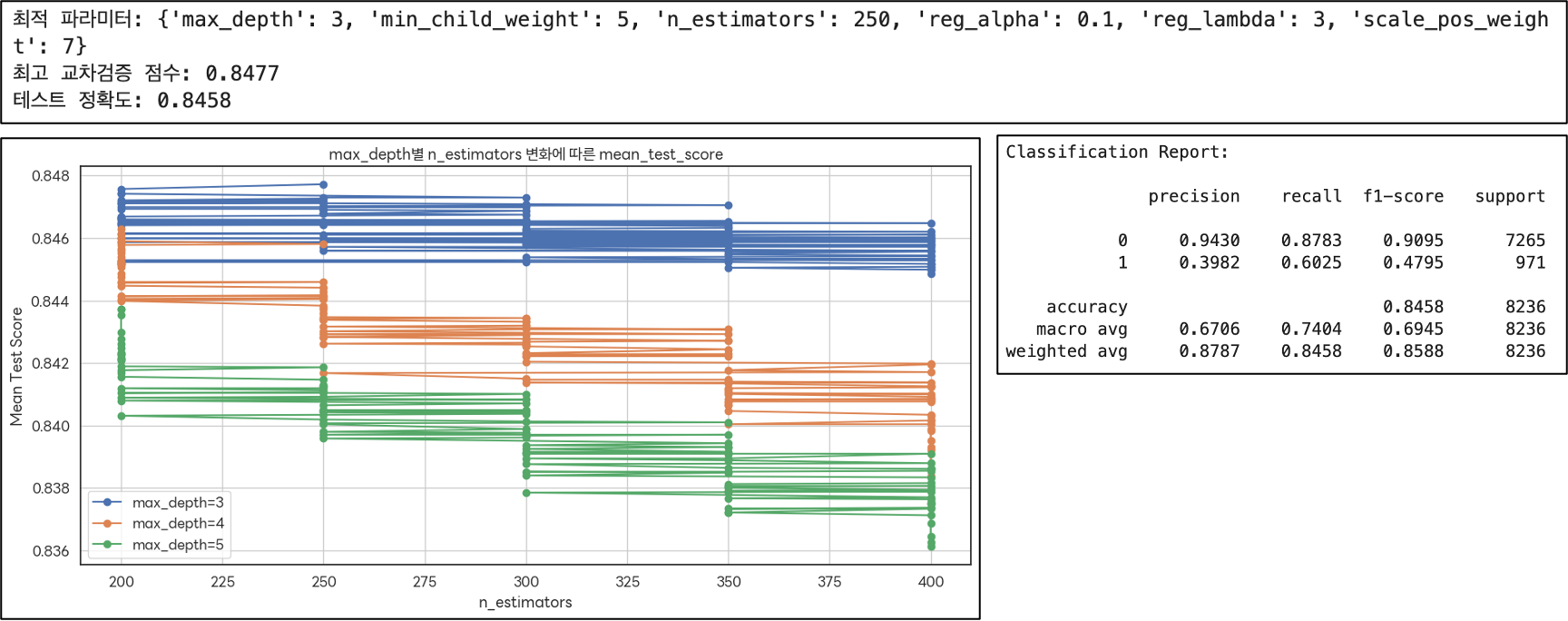
(max_depth = 3)
: 가장 높은 mean_test_score를 보이며, 특히 n_estimators가 200-300 사이일 때 성능이 좋다.
(최적의 모델 선택)
: max_depth=3과 max_depth=4의 경우가 유리하지만, 복잡도와 안정성을 고려할 때 max_depth=3가 상대적으로 더 좋은 선택으로 보인다.
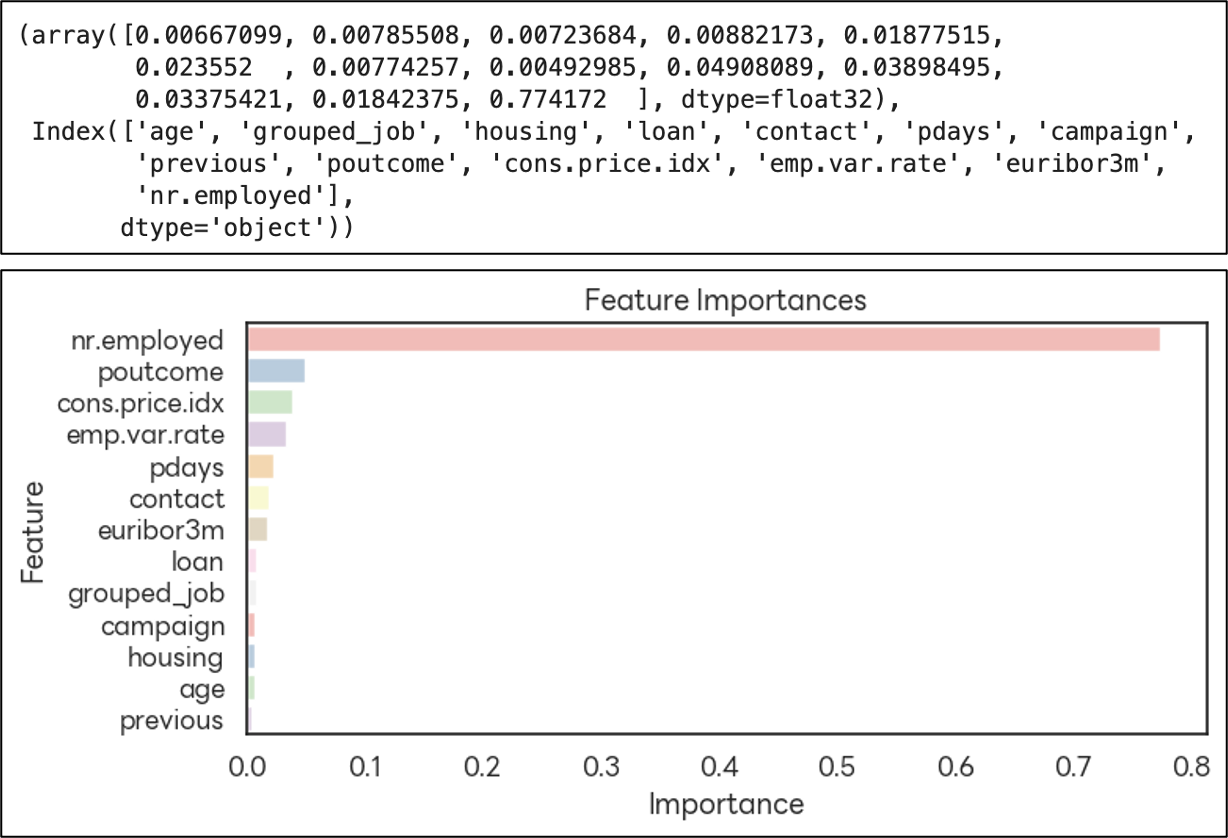
(nr.employed)
: nr.employed 변수 하나만으로도 모델 예측의 대부분을 설명하고 있다. (0.77)
: 전체 고용 수치(nr.employed)가 고객의 예금 가입 여부와 매우 밀접하게 연관되어 있다는 것을 의미한다.
(모델의 학습 편향 가능성이 의심됨)
: nr.employed를 제외한 특성들의 중요도가 미미하다.
☑️ 평가
| 모델 | 정확도 | Precision | Recall | F1-score | 평가 요약 |
| Decision Tree | 0.89 | 0.73 | 0.16 | 0.26 | 과적합 의심 실질적 성능이 떨어짐 |
| Random Forest | 0.8763 | 0.4646 | 0.4646 | 0.3820 | 보수적 예측 Precision 우위 |
| XGBoost | 0.8458 | 0.3982 | 0.6025 | 0.4795 | 가장 균형적인 성능 실제 가입자를 잘 포착함 |
1. F1-score가 가장 높아 모델의 전반적 성능이 가장 우수 / 실제 예금 가입자를 최대한 포착하고 싶은 경우
→ XGBoost가 가장 적합
2. 반대로 예측 정확도와 해석 가능성을 중시하고, FP(False Positive)을 줄이는 게 중요한 경우
→ Random Forest 선택 가능
3. Decision Tree는 간단한 모델 해석에는 유용할 수 있으나, 성능상 선택 우선순위는 낮음
'📗 개인 프로젝트 > 🏦 정기 예금 가입 여부 예측' 카테고리의 다른 글
| 🏦 정기 예금 가입 여부 예측 | 4️⃣ 파일 업로드 (0) | 2025.04.21 |
|---|---|
| 🏦 정기 예금 가입 여부 예측 | 3️⃣ 비즈니스 전략 제안 (0) | 2025.04.21 |
| 🏦 정기 예금 가입 여부 예측 | 1️⃣ EDA (0) | 2025.04.21 |